CUDA on Arm-GPU硬件架构
🎉感谢来自NVIDIA企业级开发者社区的何琨(Ken)老师提供的资料和细致耐心的讲解
GPU简介
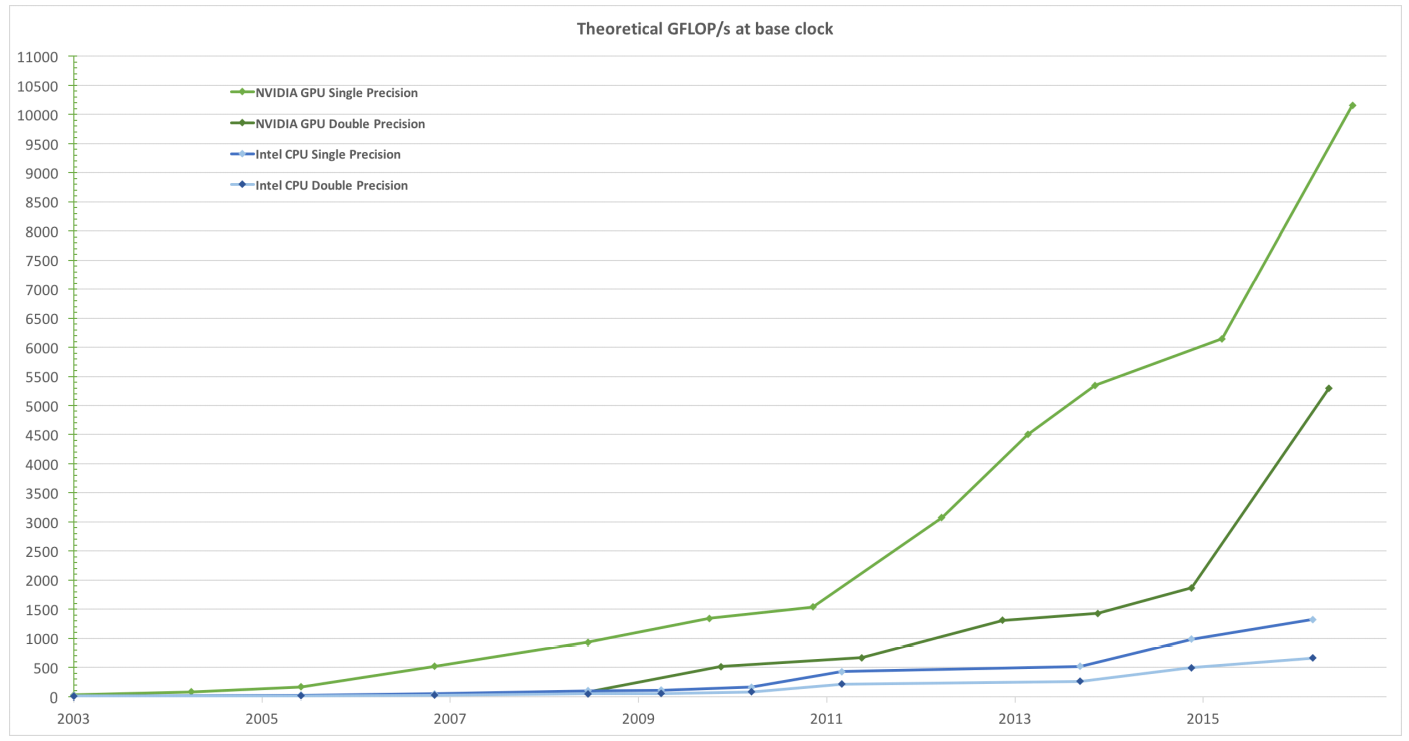
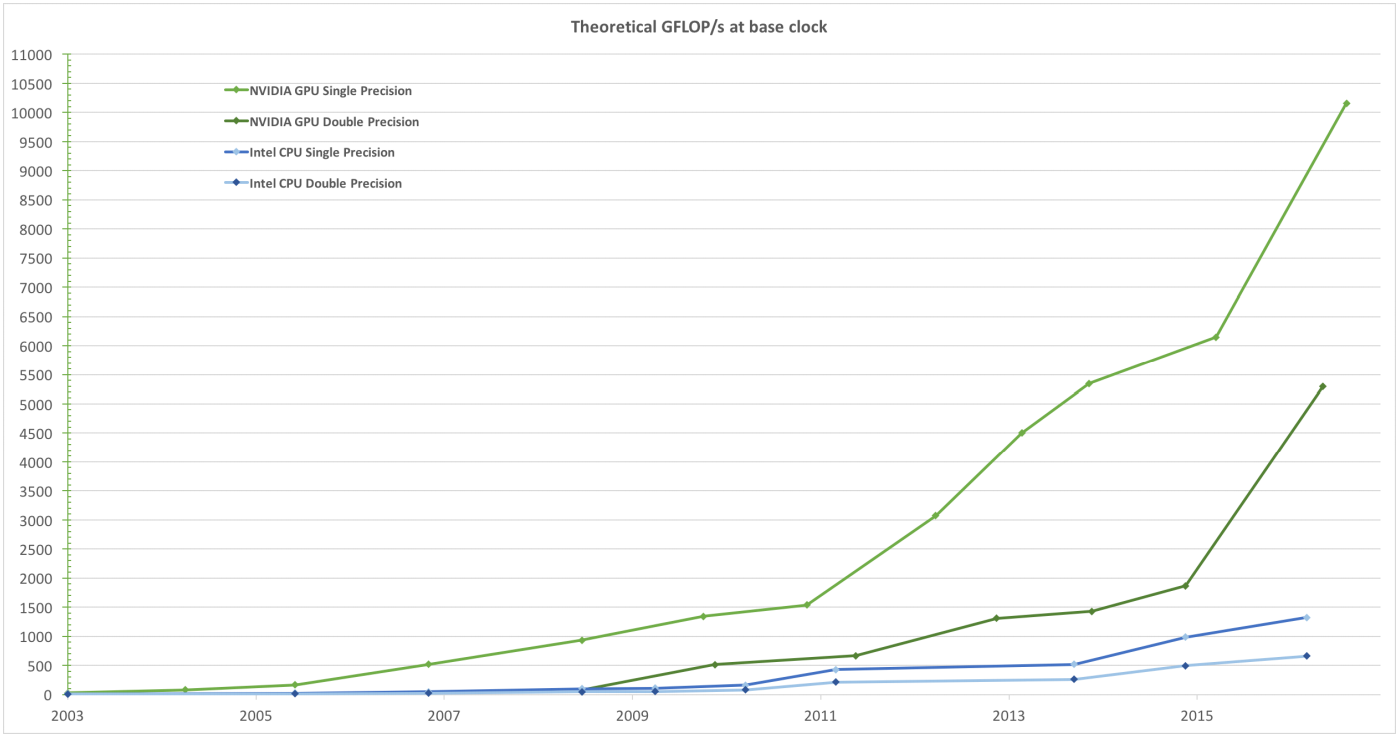
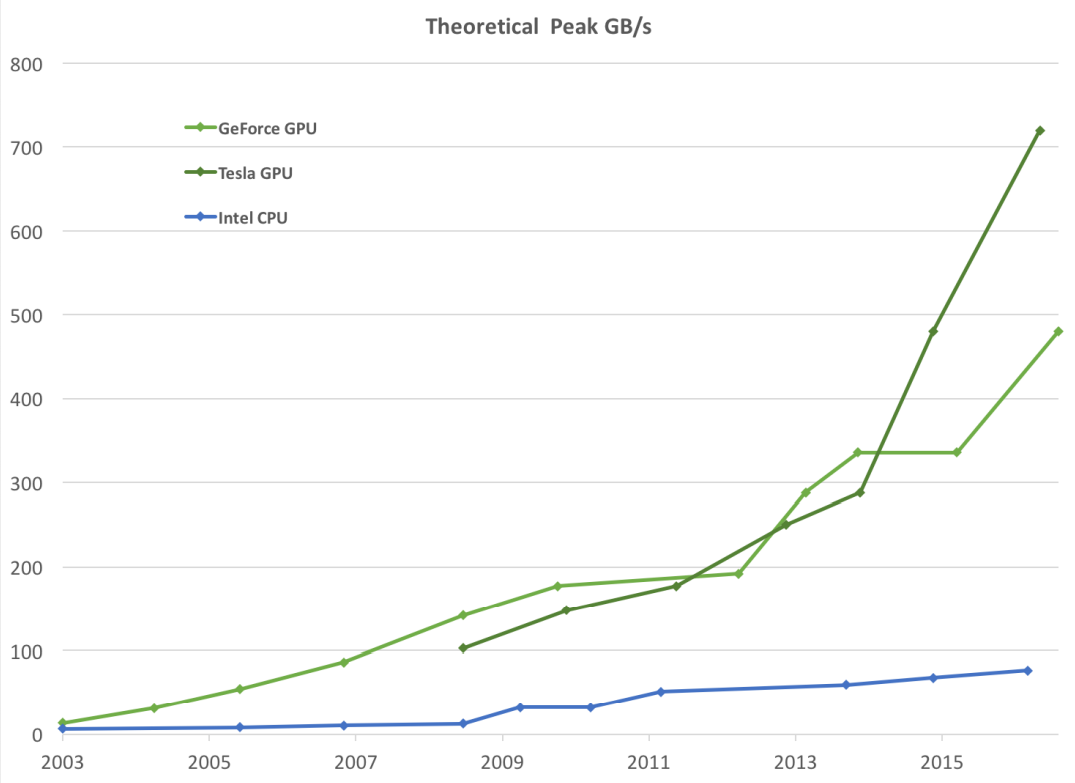
GPU计算性能变迁
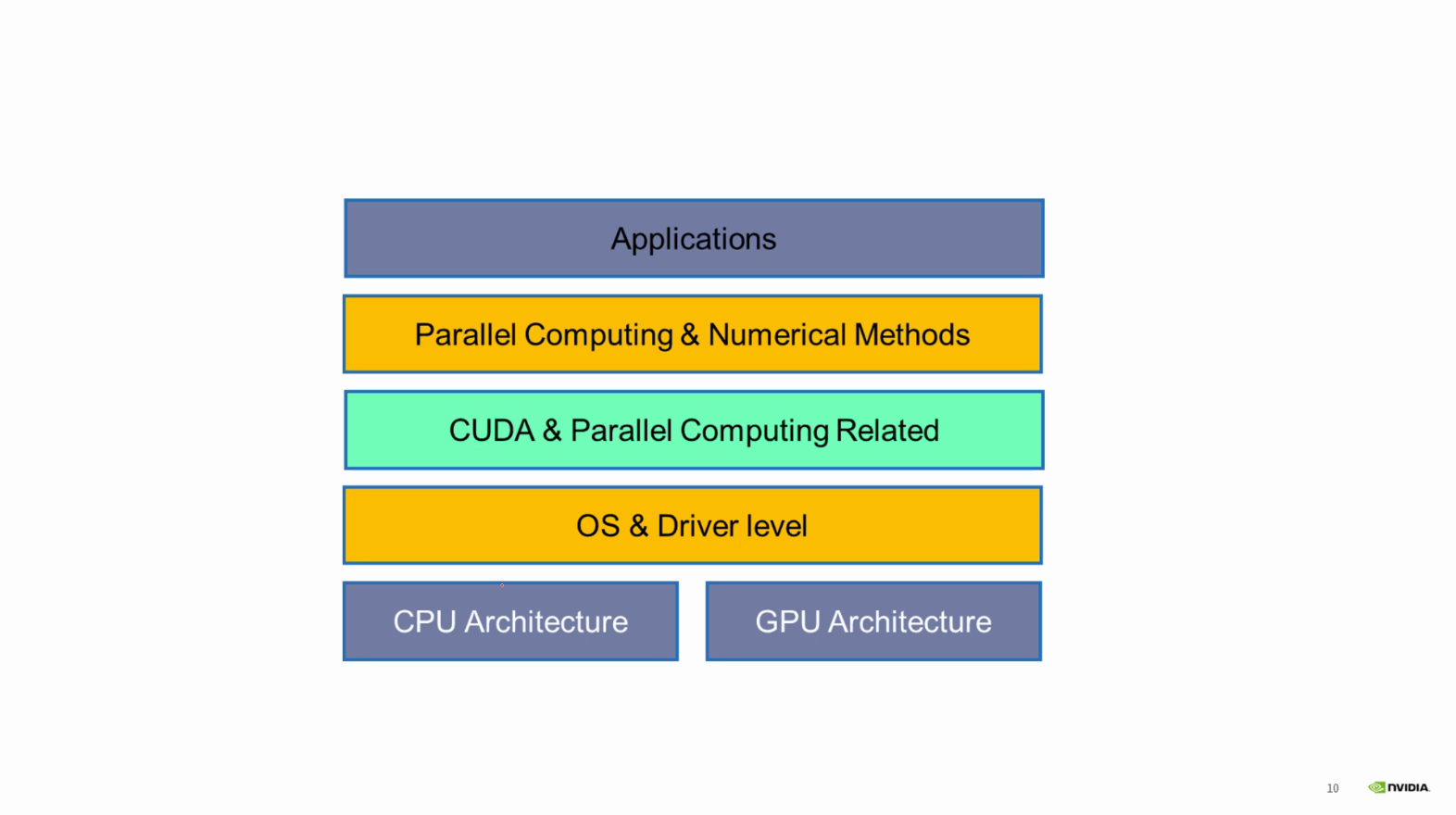
体系结构层次
更快的计算机
更多的晶体管
截至今日(2021-8-21)最新的Intel Alder Lake CPU构架如下图所示 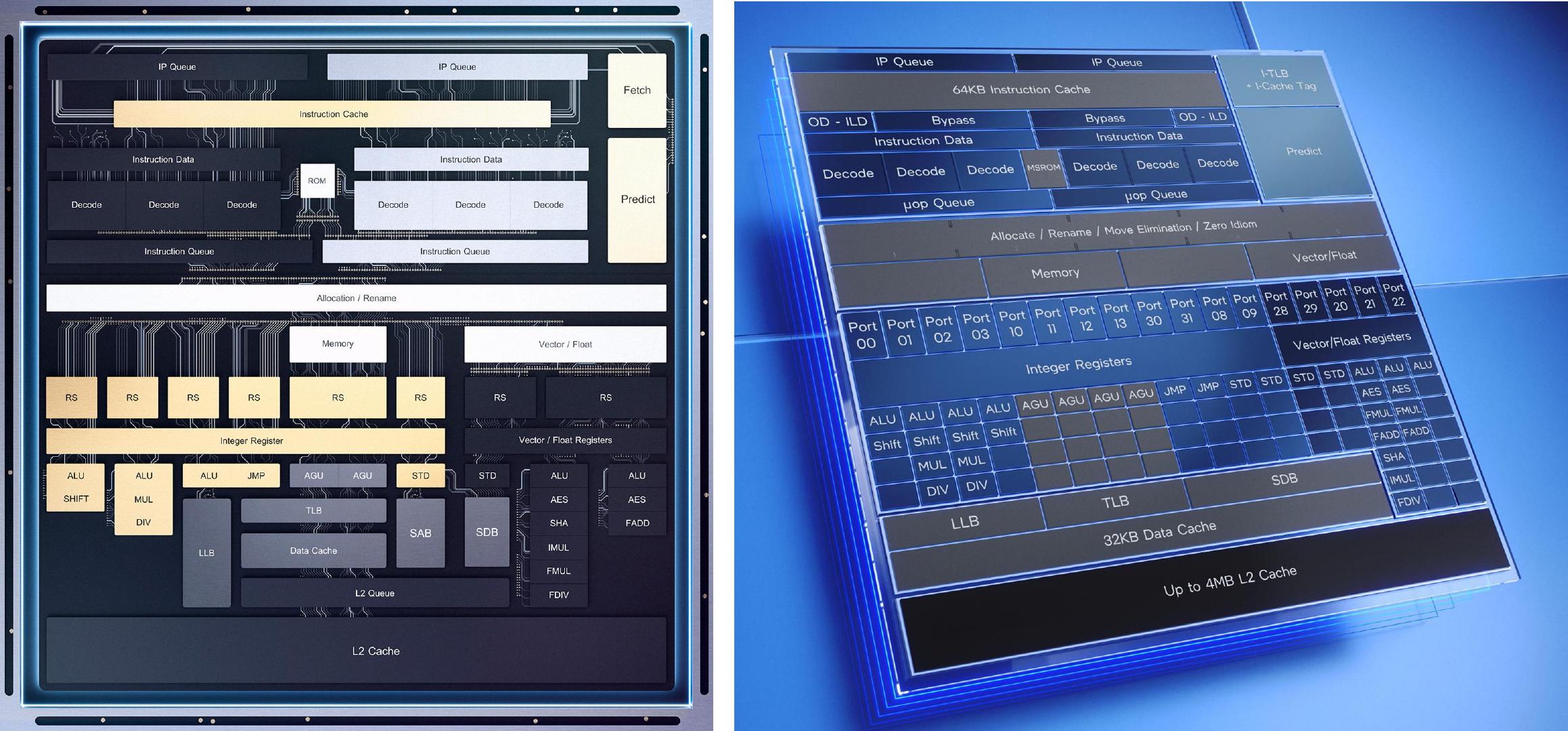
摩尔定律
芯片的集成密度每2年翻翻,成本下降一半。
可是…….
常规传统单核处理器遇到物理约束,时钟频率〔perf/clock]无法保持线型增长。
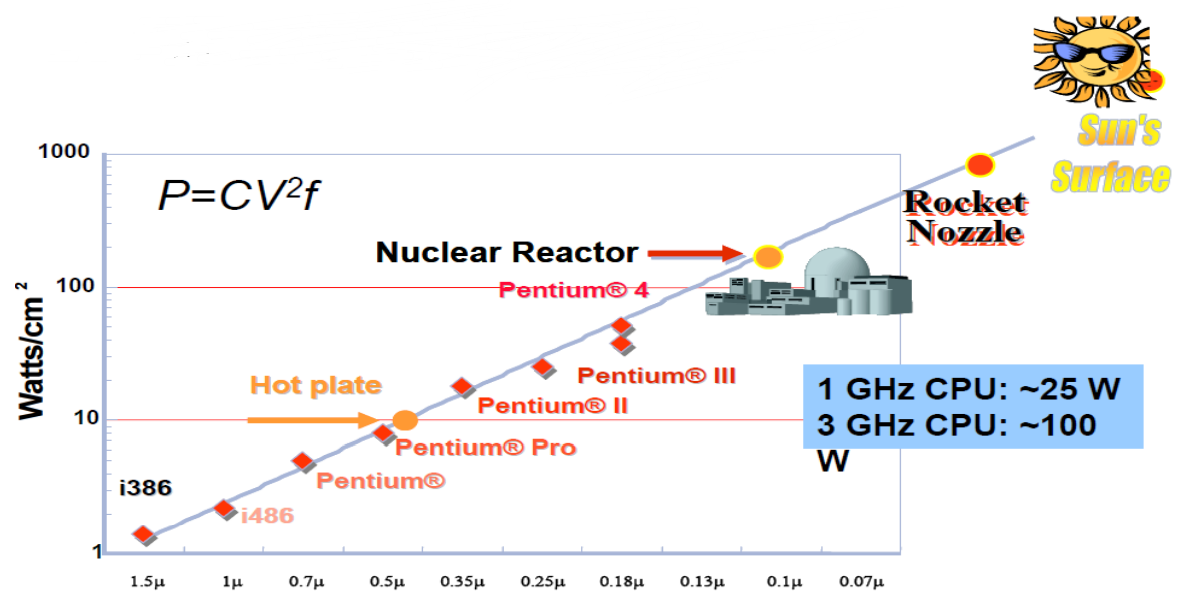
现在的CPU系统已经遇到各种瓶颈,只能向多核及并行系统发展。
顺势而生的GPU- Graphics Processing Unit如下图

GPU计算性能与数据带宽
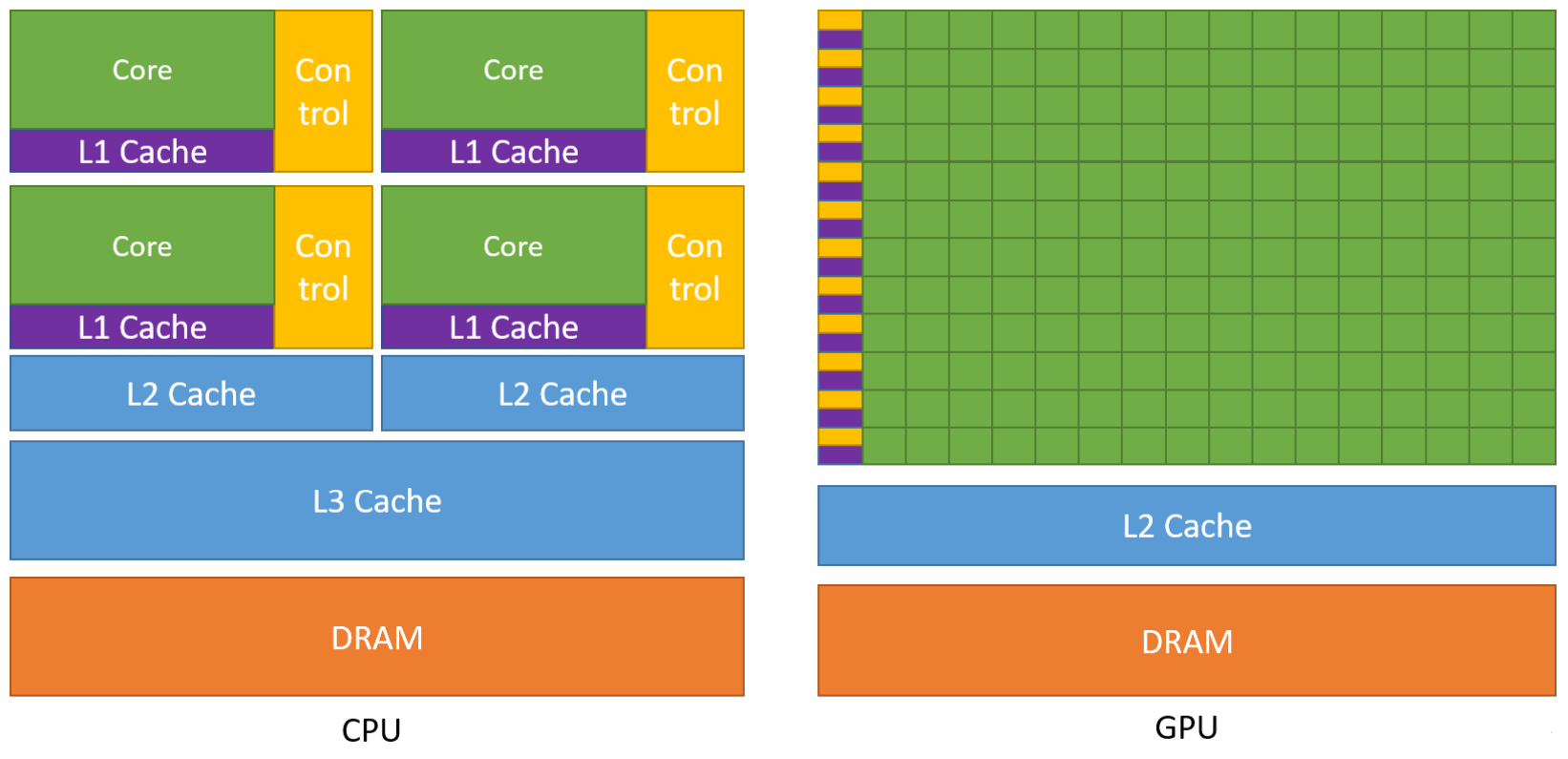
GPU设计思想
内核设计
CPU类型的内核
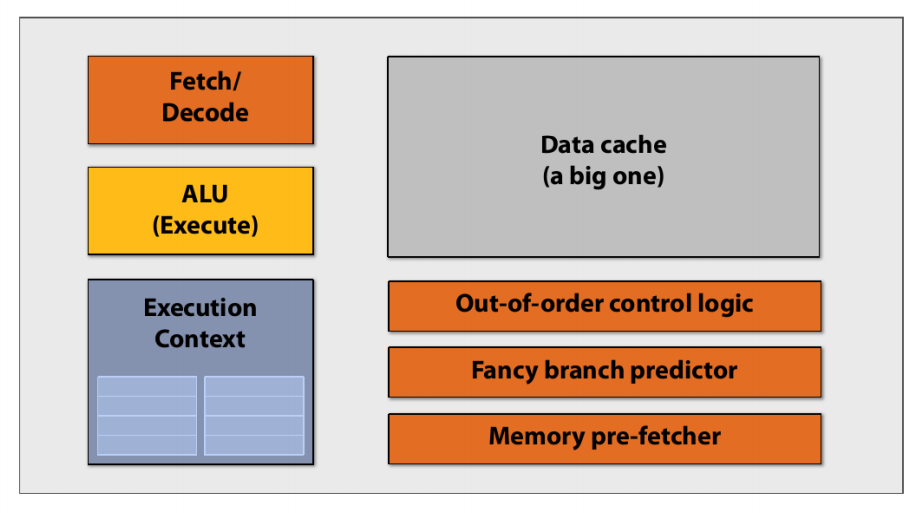
实际上正真用于计算的单元在内核面积中占比并不算高,更多的都是用于控制和存储的机构,例如对于指令流水线、乱序执行、分支预测等支持部件。而GPU内核就在此基础上精简掉不必要的结构,先安排计算核心而后考虑别的方法去添加控制与存储部件。
精简后的CPU内核

将多个这样精简后的内核组合到一块就得到了GPU内核的雏形。
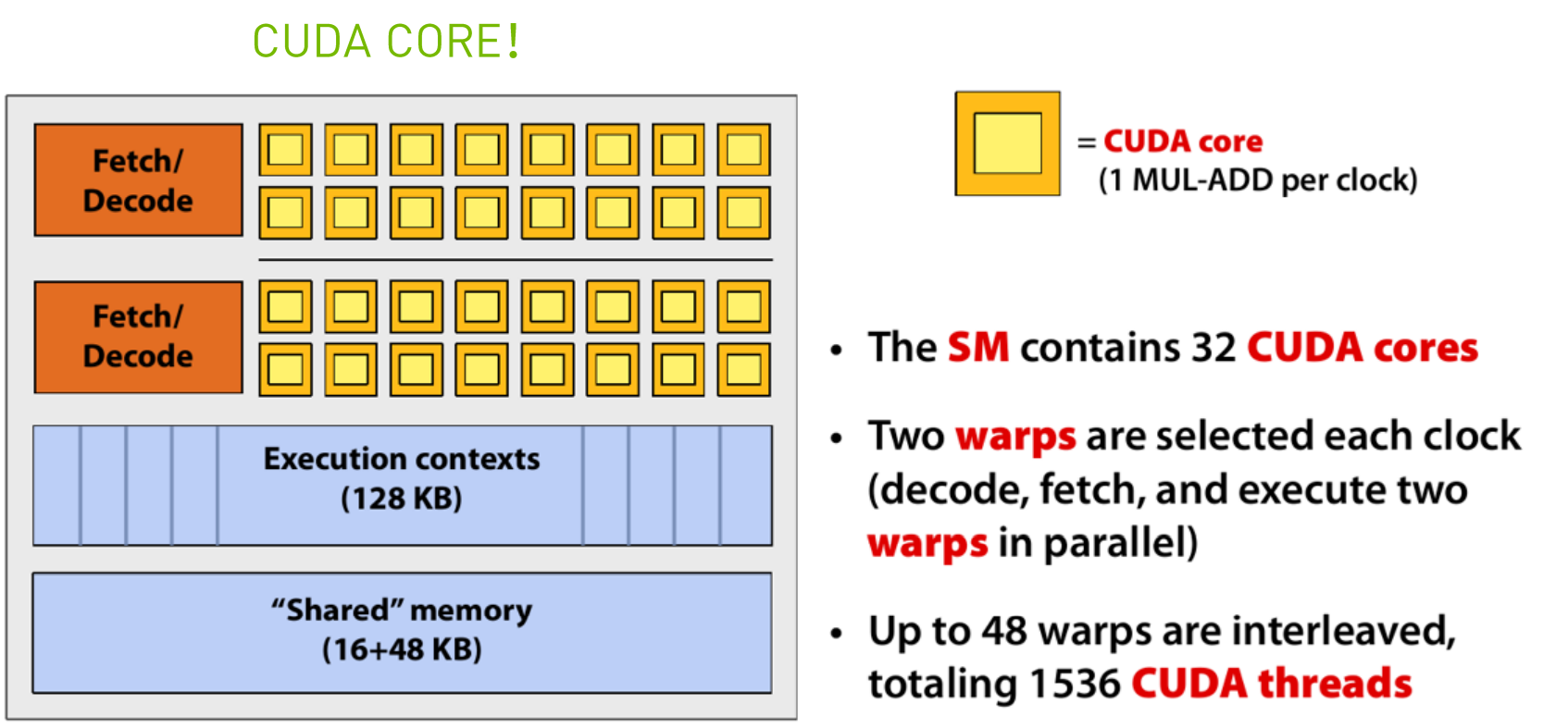
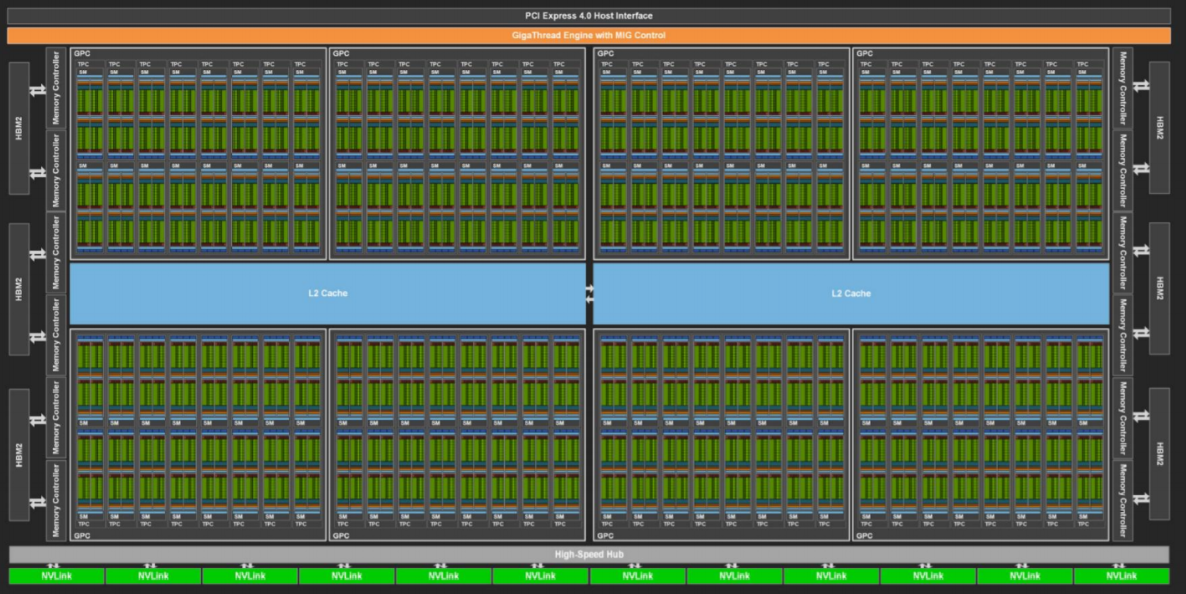
芯片结构
GA-100结构
GPU on Arm

GPU应用场景
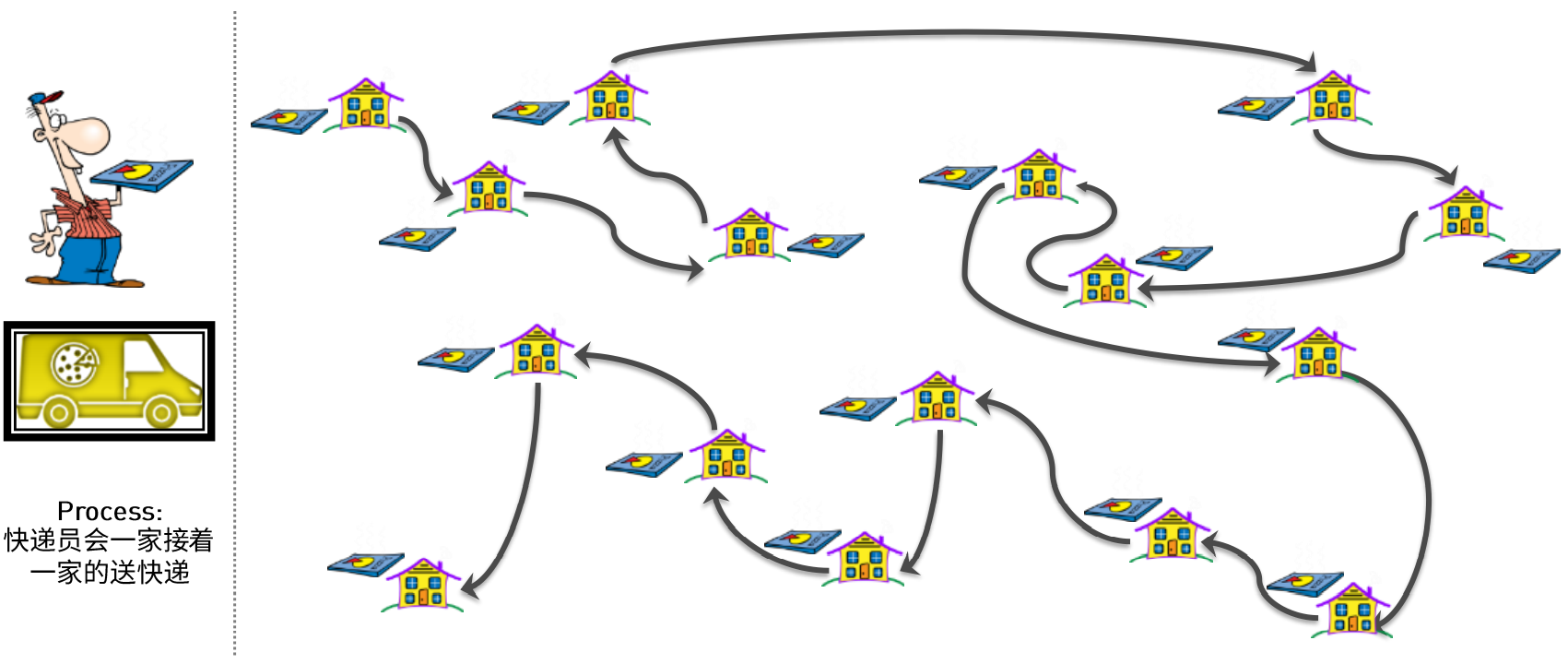
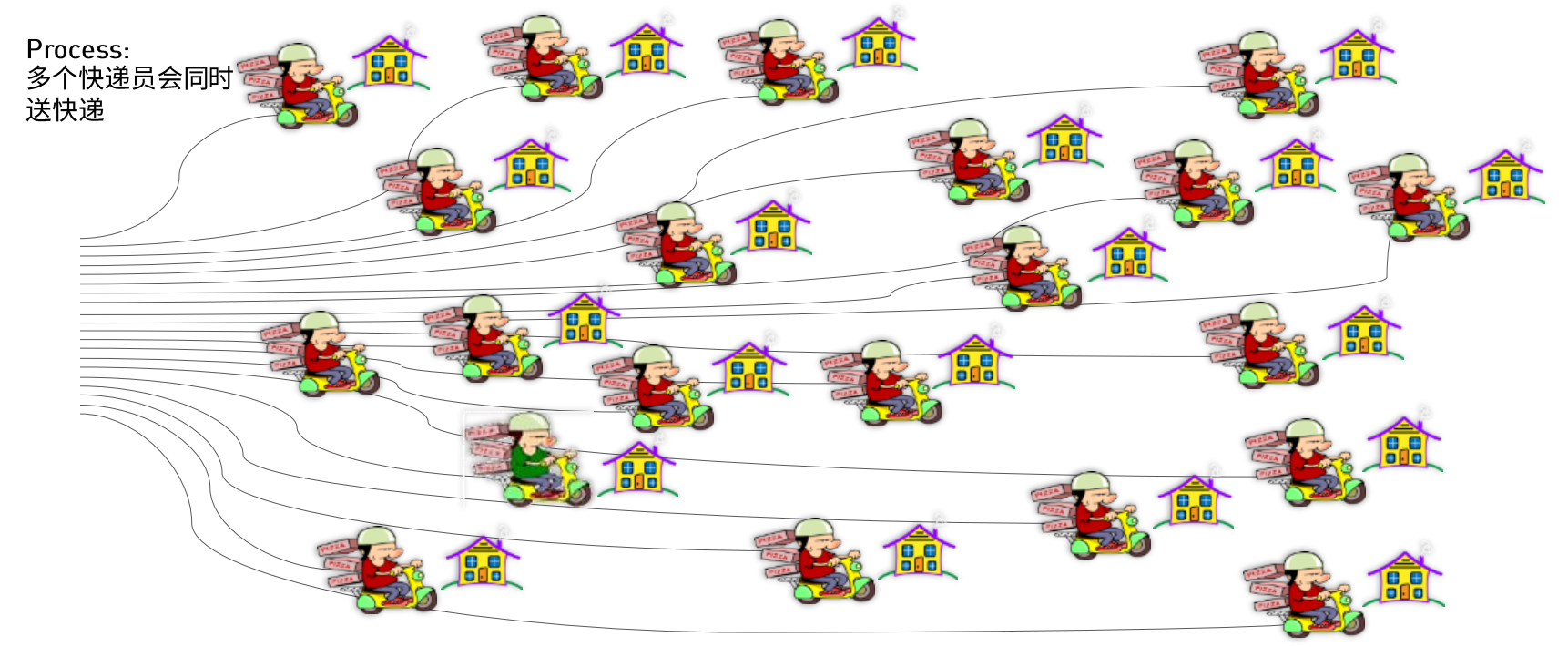
快递员送披萨问题
CPU处理
GPU处理
CUDA并行计算模式
- 并行计算是同时应用多个计算资源解决一个计算问题。
- 涉及多个计算资源或处理器。
- 问题被分解为多个离散的部分,可以同时处理(并行),每个部分可以由一系列指令完成。
- 最好是计算密集的任务,通信和计算开销比例合适,不要受制于访存带宽。
程序并行化加速比
程序可能的加速比取决于可以被并行化的部分
- 如果没有可以并行化的,
P = 0and thespeedup = 1[no speedup]。 - 如果全部都可以并行化,
P = 1and the speedup is infinite [in theory]。 - 如果50%可以并行化,
maximum speedup = 2。
如果有N个处理器并行处理
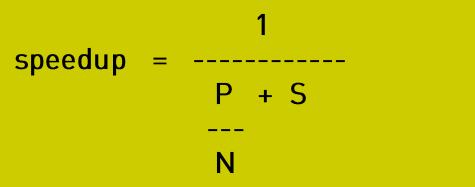
P = 并行部分,N = 处理器数量,s = 串行部分。
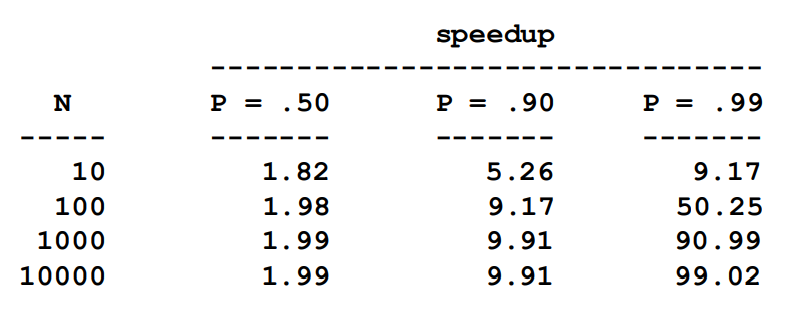
并行化的可扩展性有极限
For example, at P = .50, .90 and .99 [50%,90% and 99% of the code isparallelizable]
CUDA on Arm-GPU硬件架构
https://jason-xy.github.io/2021/08/cuda-on-arm-gpuhardware/