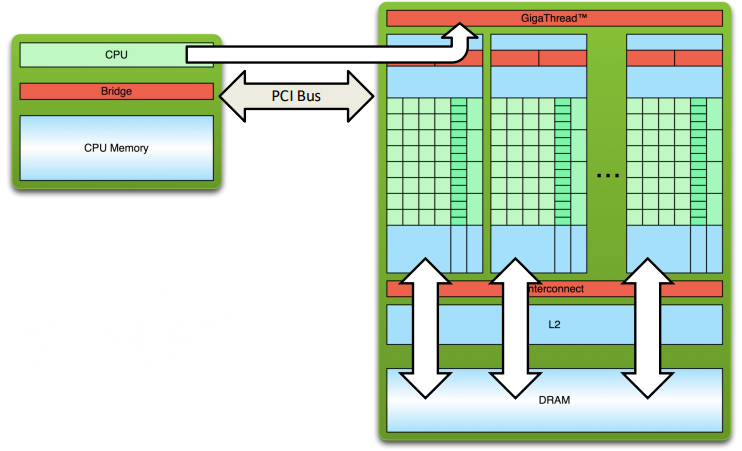
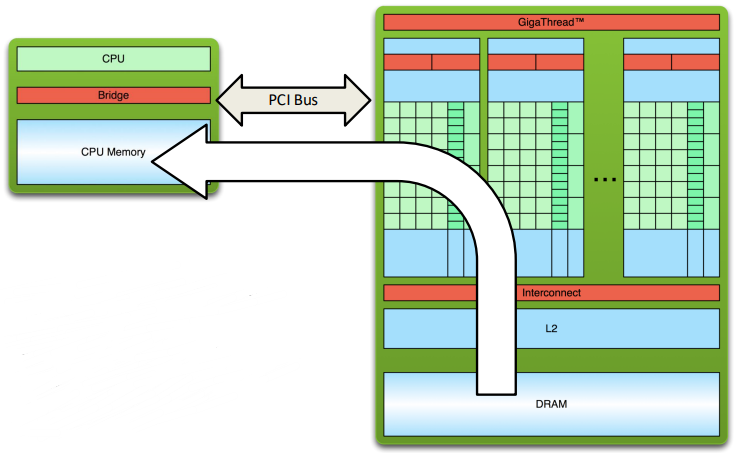
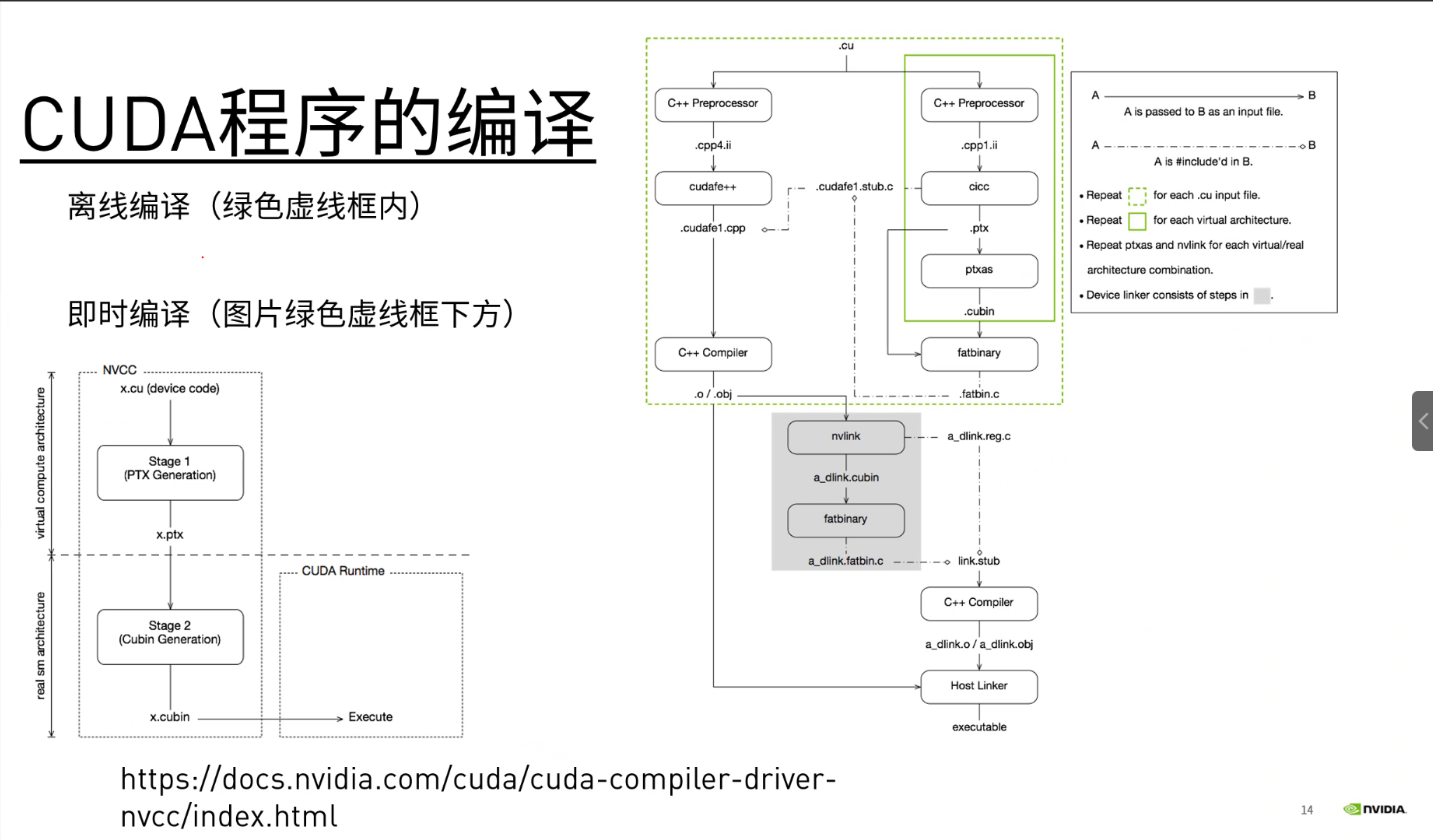
Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU!
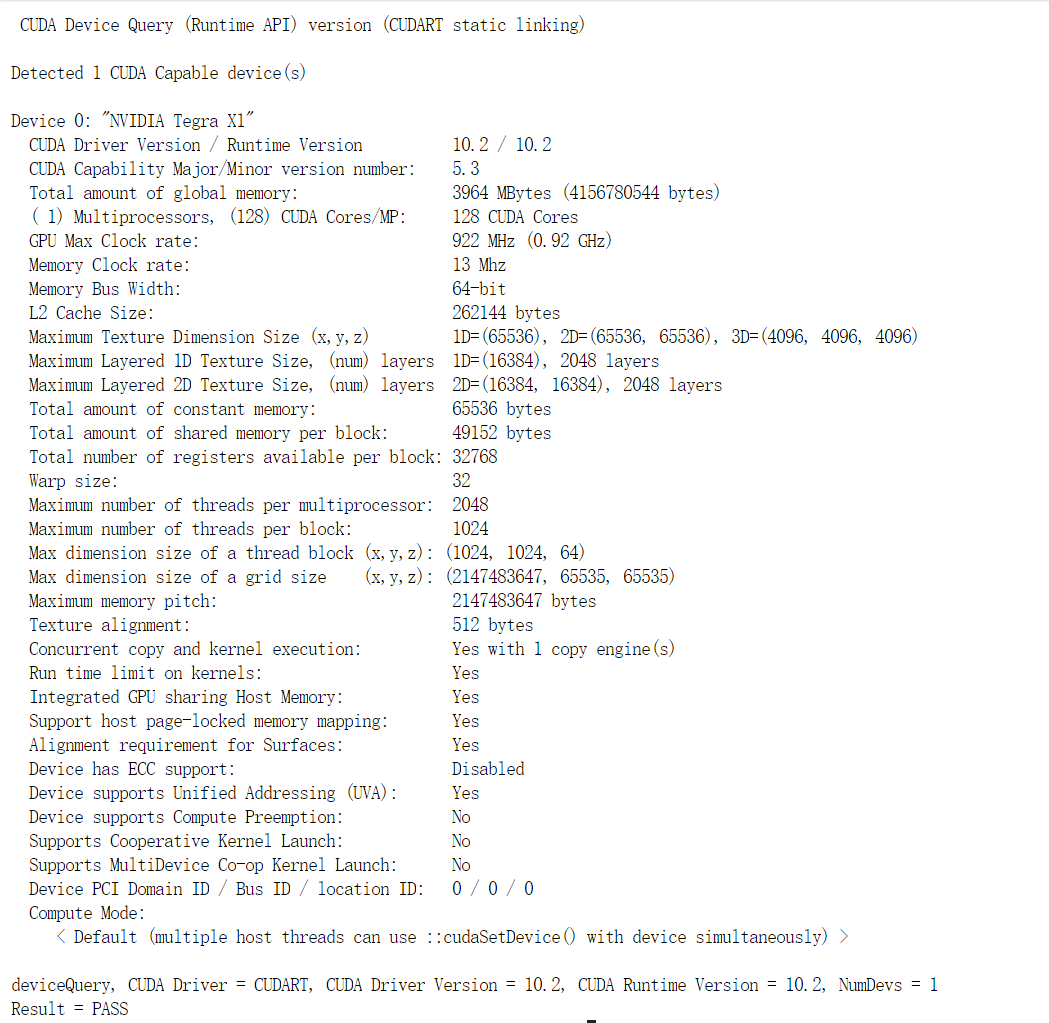
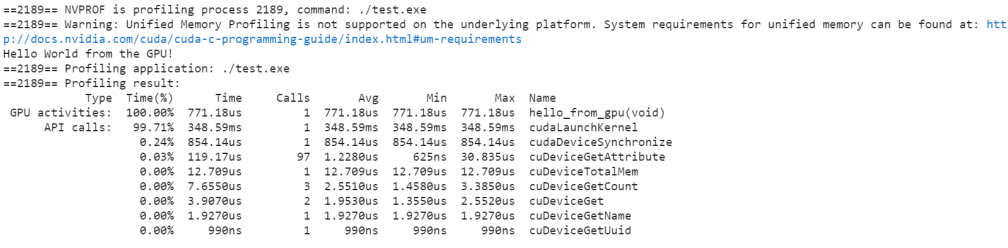
==17055== NVPROF is profiling process 17055, command: ./hello_cuda ==17055== Warning: Unified Memory Profiling is not supported on the underlying platform. System requirements for unified memory can be found at: http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#um-requirements Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! Hello CUDA from GPU! ==17055== Profiling application: ./hello_cuda ==17055== Profiling result: Type Time(%) Time Calls Avg Min Max Name API calls: 99.89% 361.69ms 1 361.69ms 361.69ms 361.69ms cudaLaunchKernel 0.06% 213.18us 97 2.1970us 960ns 58.272us cuDeviceGetAttribute 0.04% 136.67us 1 136.67us 136.67us 136.67us cudaDeviceSynchronize 0.01% 21.152us 1 21.152us 21.152us 21.152us cuDeviceTotalMem 0.00% 10.432us 3 3.4770us 1.5360us 5.4720us cuDeviceGetCount 0.00% 8.0320us 2 4.0160us 2.1440us 5.8880us cuDeviceGet 0.00% 2.9120us 1 2.9120us 2.9120us 2.9120us cuDeviceGetName 0.00% 1.5040us 1 1.5040us 1.5040us 1.5040us cuDeviceGetUuid