🎉感谢来自NVIDIA企业级开发者社区的何琨(Ken)老师提供的资料和细致耐心的讲解
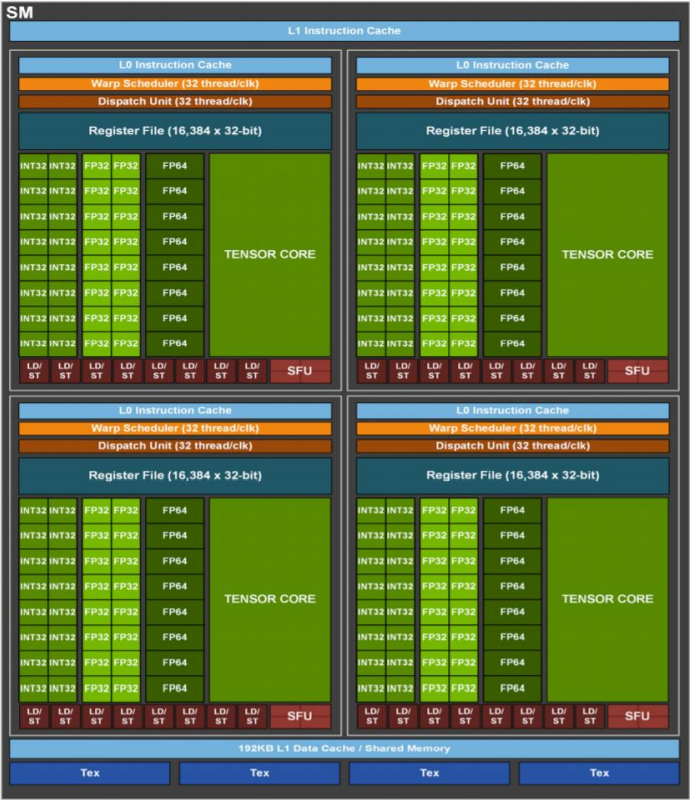
线程层次
Thread: sequential execution unit
Thread Block: a group of threads
- 执行在一个Streaming Multiprocessor [SM]
- 同一个Block中的线程可以协作
Thread Grid: a collection of thread blocks
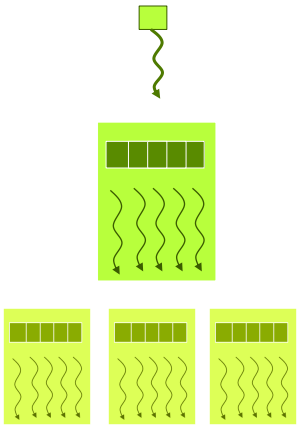
执行设置
1
| dim3 grid(3,2,1), block(5,3,1)
|
如下图所示👇
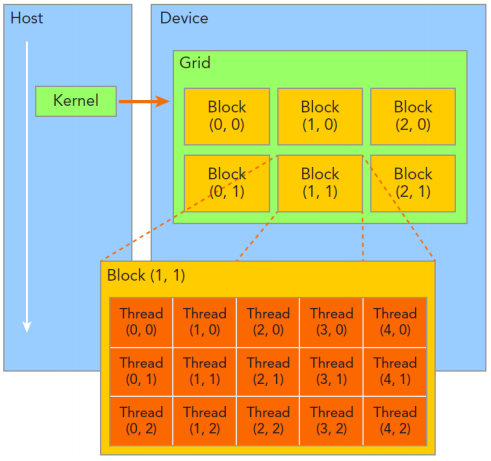
内建变量
threadldx.[x yz]
- 是执行当前kernel函数的线程在block中的索引值
blockldx.[x y z]
- 是指执行当前kernel函数的线程所在block,在grid中的索引值
blockDim.lx y z]
gridDim.[x y z]
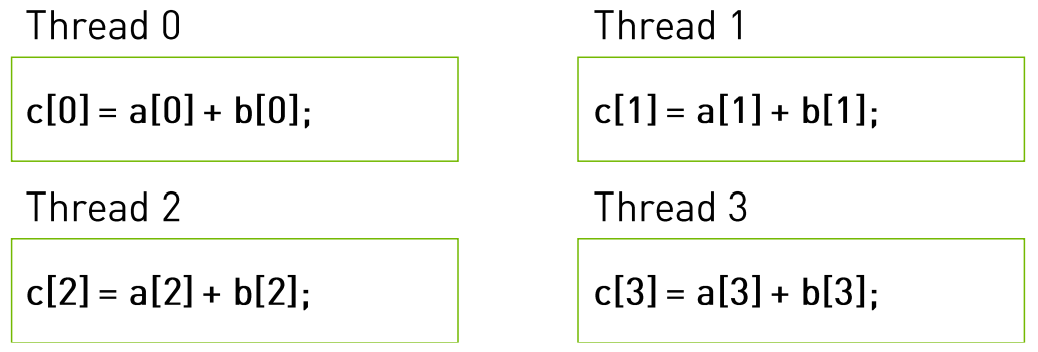
执行配置举例
代码:
1
2
3
4
| __global__ void add( int *a, int *b,int *c ) {
c[threadIdx.x] = a[threadIdx.x]+ b[threadIdx.x];
}
add<<<1,4>>>( a, b, c );
|
实际运行的样子:
软硬件对应关系
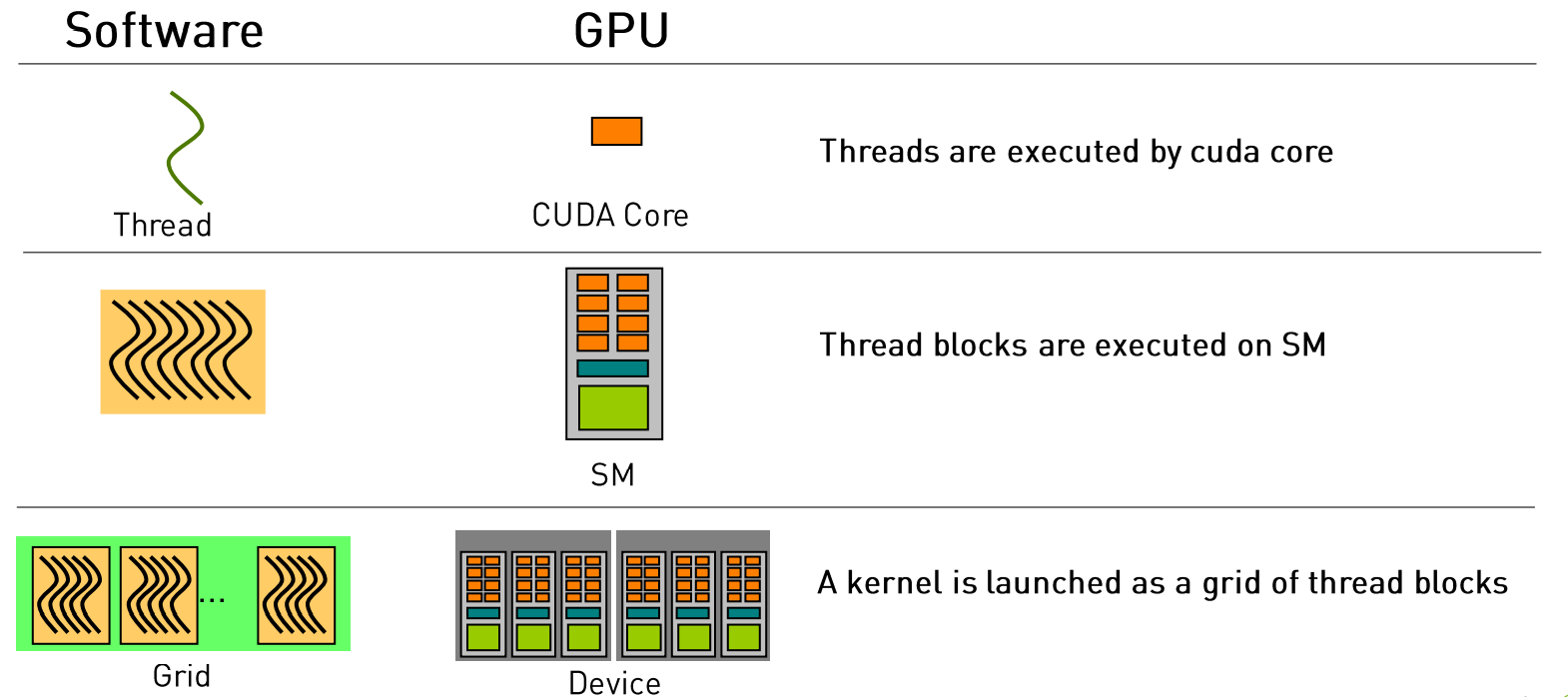
这也说明了为什么不只有线程,而引入块和网格的概念的原因,这都是与GPU硬件架构息息相关的。
CUDA的执行流程
- 加载核函数。
- 将Grid分配到一个Device。
- 根据<<<..>>>内的执行设置的第一个参数,Giga threads engine将block分配到SM中。一个Block内的线程一定会在同一个SM内,一个SM可以有很多个Block。
- 根据<<<..>>>内的执行设置的第二个参数,Warp调度器会将调用线程。
- Warp调度器为了提高运行效率,会将每32个线程分为一组,称作一个warp。
- 每个Warp会被分配到32个core上运行。
硬件调度
- Grid:GPU(GPC)级别的调度单位
- Block(CTA):SM级别的调度单位
- Threads/Warp:CUDA core级别的调度单位
资源和通信
- Grid:共享同样的kernel和 Context
- Block(CTA):同一个SM(Streaming Multi processor),同一个SM(Shared Memory)
- Threads/Warp:允许同一个warp中的thread读取其他thread的值
CUDA的线程索引
确定线程执行的数据
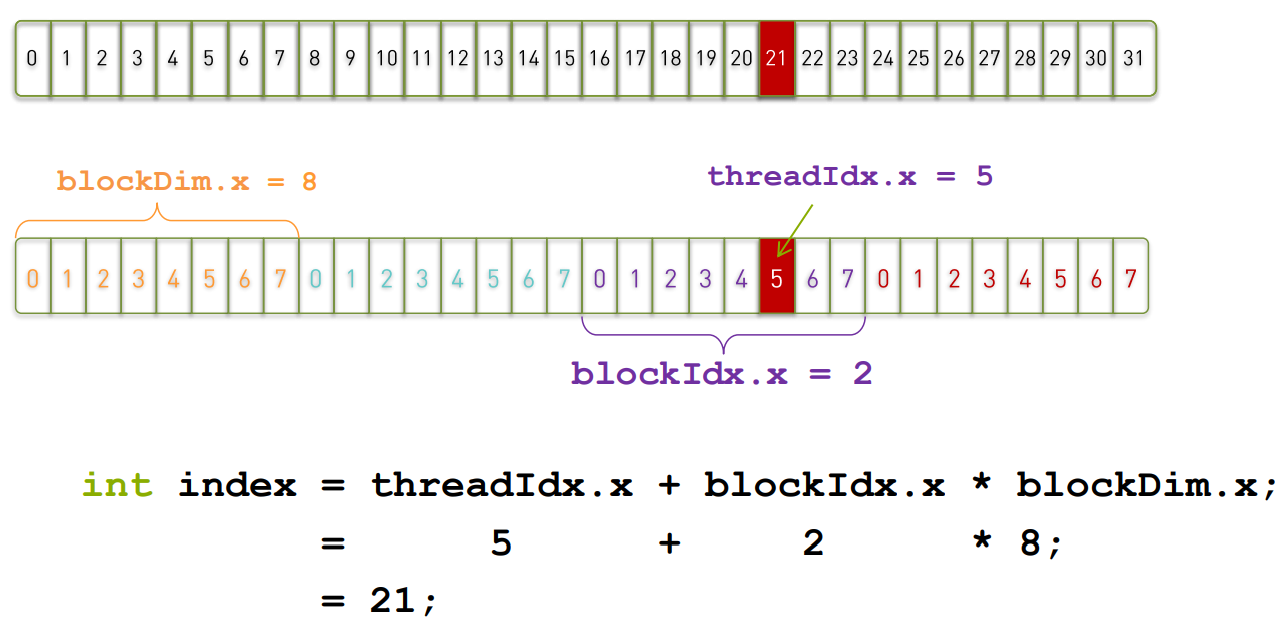
例如:
1
2
3
4
5
| __global__ void add(const double *x, const double*y, double *z)
{
const int n = blockDim.x * blockldx.x + threadldx.x;
z[n] = x[n]+ y[n];
}
|
每个线程都执行相同的指令。
实验(VectorAdd 矩阵加法)
实验代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #include <math.h>
#include <stdio.h>
void __global__ add(const double *x, const double *y, double *z)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] + y[n];
}
void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double *h_x = (double*) malloc(M);
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
double *d_x, *d_y, *d_z;
cudaMalloc((void **)&d_x, M);
cudaMalloc((void **)&d_y, M);
cudaMalloc((void **)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128;
const int grid_size = (N + block_size - 1) / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
|
代码解析
核函数
1
2
3
4
5
| void __global__ add(const double *x, const double *y, double *z)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] + y[n];
}
|
核函数就是给每一个线程分配的任务,这里将矩阵的每一个数据由一个线程处理,那么每一个线程只需要处理一个加法即可。
每一个线程处理的数据由线程id决定(在所有线程中的id),这里的n = blockDim.x * blockIdx.x + threadIdx.x便计算出了线程索引,正好与数据索引一一对应,由此便实现了单指令多数据的并行处理。
校验函数
1
2
3
4
5
6
7
8
9
10
11
12
| void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
|
将CPU计算结果作为基准与GPU计算结果对比校验是否计算正确。
主函数部分
1
2
3
4
5
| const int N = 100000000;
const int M = sizeof(double) * N;
double *h_x = (double*) malloc(M);
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
|
定义变量,并在host(CPU)中分配存储空间。
1
2
3
4
5
| for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
|
给输入矩阵赋初值。
1
2
3
4
5
6
| double *d_x, *d_y, *d_z;
cudaMalloc((void **)&d_x, M);
cudaMalloc((void **)&d_y, M);
cudaMalloc((void **)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
|
定义变量后,使用cudaMalloc在device(GPU)中分配空间,使用cudaMemcpy将数据从host内存拷贝到device内存。
cudaMalloc((void **)ptr, size_byte)中ptr是一个指向device memory地址的指针,所以这里是一个双重指针,size_byte就是分配的空间大小了,以字节为单位。
cudaMemcpy(dst, src, size_byte, direction)中 direction是指传输方向,具体的可选项请查询手册。
1
2
3
| const int block_size = 128;
const int grid_size = (N + block_size - 1) / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z);
|
这里是核函数执行配置及调用,也就是程序开始并行化的部分。
关于执行配置的详细说明见后文。
1
2
| cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
check(h_z, N);
|
将数据拷贝回host并校验数据正确性。
cudaMemcpy中隐式执行了设备同步所以不用显示调用cudaDeviceSynchronize()来完成同步。
1
2
3
4
5
6
| free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
|
释放内存,程序结束。
编译:
1
| nvcc vectorAdd.cu -o vectorAdd
|
输出:
可能的问题
如何设置Gridsize & Blocksize
1
2
| block_size = 128;
grid_size =(N + block_size - 1] / block_size;
|
这样可以最大限度地少浪费线程资源。
grid_size = (n + block_size - 1) / block_size可以这么理解,如果n = a * block_size + b(a为0 or 正整数,b为小于block_size的0 or 正整数), 那么(n + block_size - 1) / block_size等价于(a * block_size + b + block_size - 1) / block_size等价于a + (b + block_size - 1) / block_size,由于会向下取整,所以(b + block_size - 1) / block_size 等价于1,最终(n + block_size - 1) / block_size = a + 1。
如果n = a * block_size + b定义为,a个线程block+个数小于block_size的零散的thread, 那么上面推导出的那个a就是值a个block,而上面推导出的+1就是为个数小于block_size的零散的thread而专门设置的block。
每个BLOCK可以申请多少个线程
在cd /usr/local/cuda/samples/1_Utilities/deviceQuery中执行./deviceQuery可以查询到如下信息:

数据过大,线程不够用怎么办
采用滑动窗口的思想来处理数据,如下图所示:
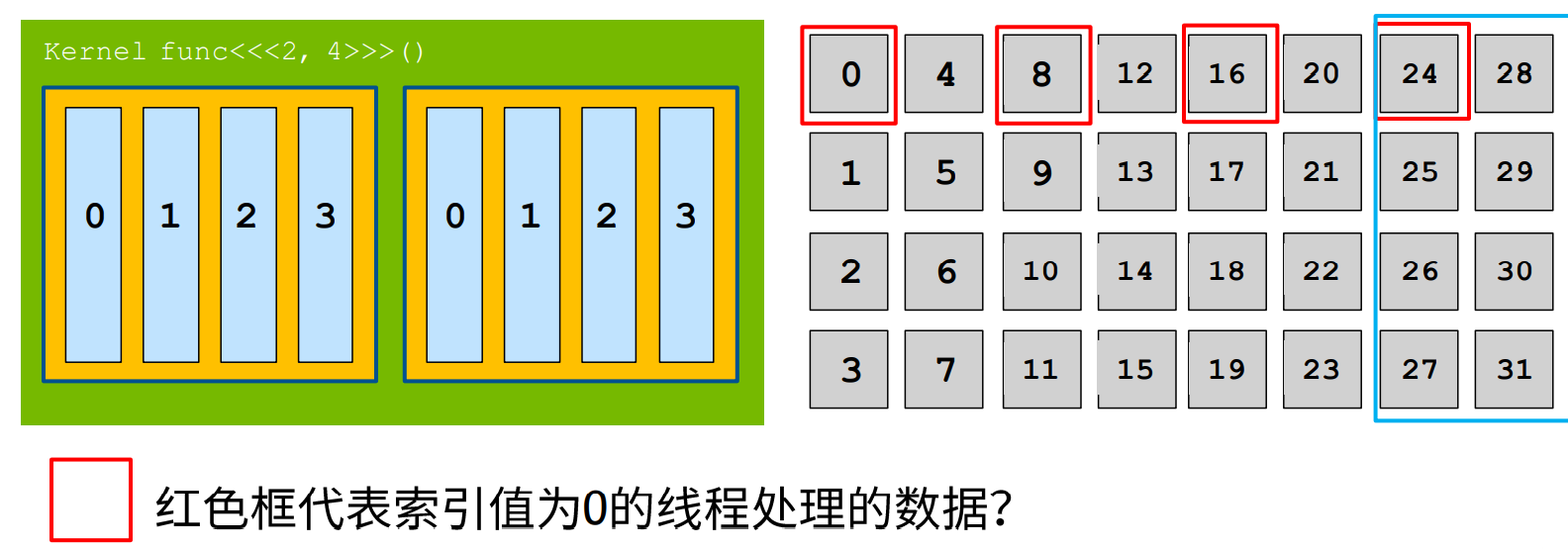
参考代码:
1
2
3
4
5
6
7
| __global__ add(const double *x, const double *y, double *z, in
{
int index = blockDim.x * blockldx.x + threadldx.x;
int stride = blockDim.x * gridDim.x;
for(; index < n; index += stride)
z[index] = x[index] + y[index];
}
|
这里的stride即为每次滑动的距离。