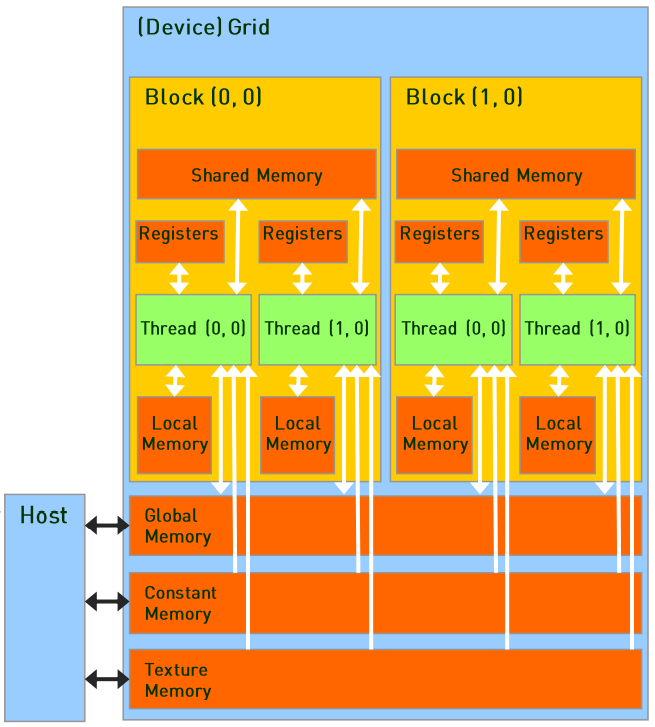
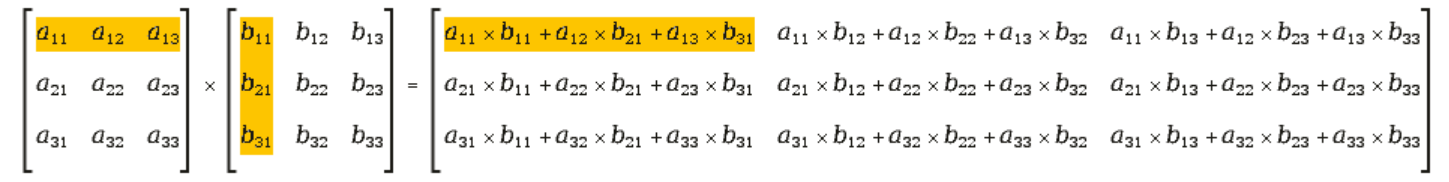cudaMemcpy(d_m, h_m, sizeof(int) * m * m, cudaMemcpyHostToDevice);
**d_m:**传输的目的地,GPU存储单元
**h_m:**数据的源地址,CPU存储单元
**sizeof(int) * m * m:**数据传输的大小
**cudaMemcpyHostToDevice:**数据传输的方向,CPU -> GPU
当我们要将准备好的数据从GPU存储单元传输到CPU的内存时
1
cudaMemcpy(h_c, d_c, sizeof(int) * m * k, cudaMemcpyDeviceToHost);
实验(矩阵乘法)
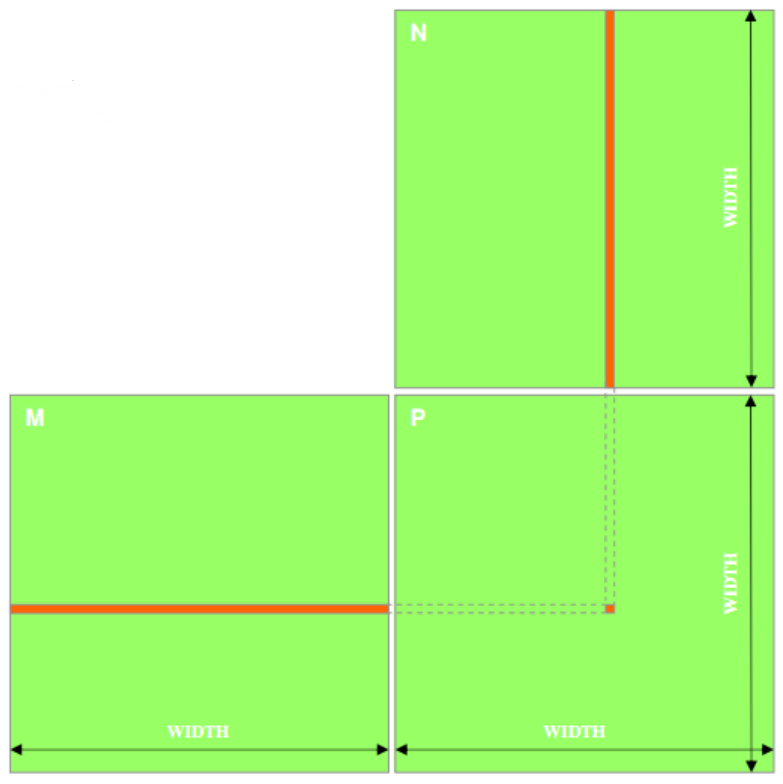
矩阵相乘计算样例:
CPU矩阵乘法
使用CPU完成这一过程:
1 2 3 4 5 6 7 8 9 10 11 12 13
voidcpu_matrix_mult(int *h_m, int *h_n, int *h_result, int m, int n, int k){ for (int i = 0; i < m; ++i){ for (int j = 0; j < k; ++j){ int tmp = 0.0; for (int h = 0; h < n; ++h){ tmp += h_m[i * n + h] * h_n[h * k + j]; } h_result[i * k + j] = tmp; } } }
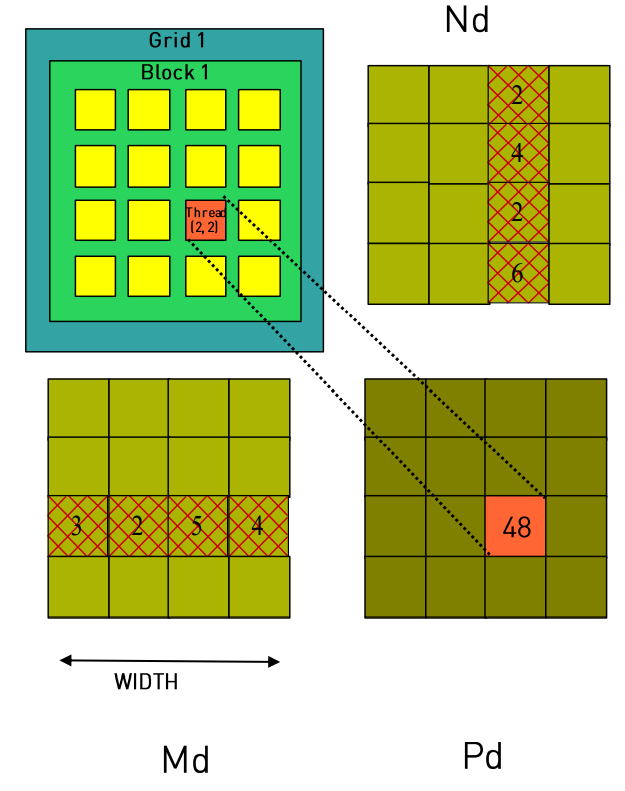
可见整个计算过程需要完成三重循环,总共需要计算m * n * k次tmp += h_m[i * n + h] * h_n[h * k + j];才能完成计算。下面采用CUDA的并行编程模型来尝试去掉部分循环进行加速。
二维网格和线程块
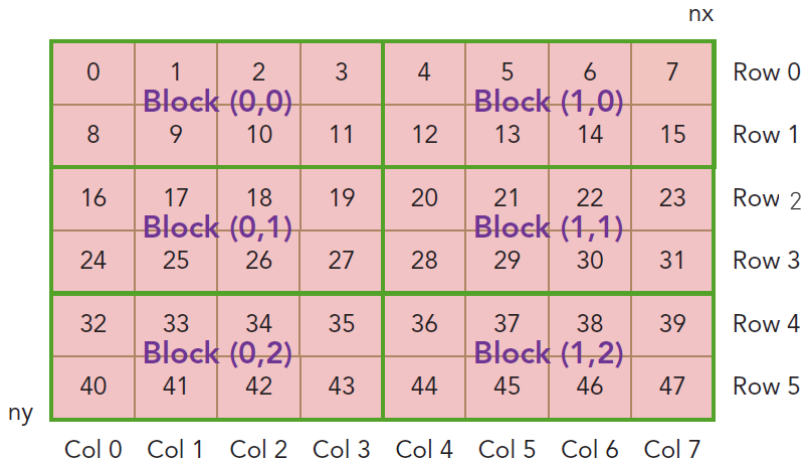
为了解决矩阵乘法的问题,需要先搞定二维状态下线程的索引计算(当然也可以转换为一维)。
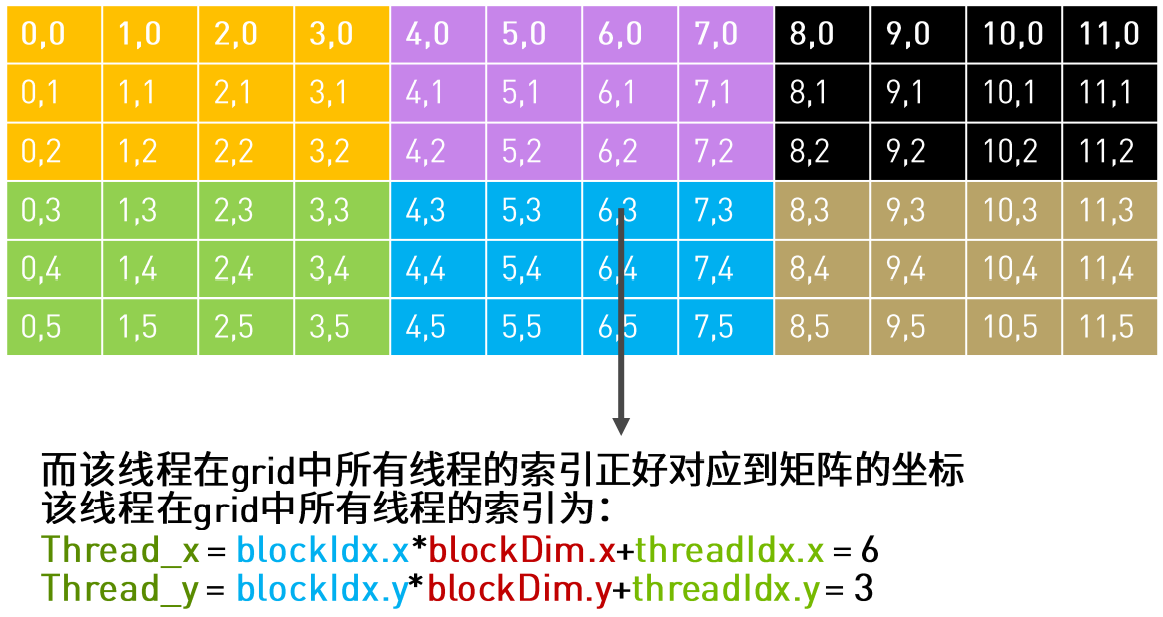
线程的索引排序方式如下图:
Global linear memory index: idx = iy * nx + ix
以44号线程为例
1
int index = (blockIdx.y * blockDim.y + threadIdx.y) * nx+ (blockIdx.x * blockDim.x + threadIdx.x);
__global__ voidgpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k) { int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; int sum = 0; if( col < k && row < m) { for(int i = 0; i < n; i++) { sum += a[row * n + i] * b[i * k + col]; } c[row * k + col] = sum; } }
voidcpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) { for (int i = 0; i < m; ++i) { for (int j = 0; j < k; ++j) { int tmp = 0.0; for (int h = 0; h < n; ++h) { tmp += h_a[i * n + h] * h_b[h * k + j]; } h_result[i * k + j] = tmp; } } }
intmain(int argc, charconst *argv[]) { int m=1000; int n=2000; int k=3000;
// copy matrix A and B from host to device memory cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
__global__ voidgpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k) { int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; int sum = 0; if( col < k && row < m) { for(int i = 0; i < n; i++) { sum += a[row * n + i] * b[i * k + col]; } c[row * k + col] = sum; } }
voidcpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) { for (int i = 0; i < m; ++i) { for (int j = 0; j < k; ++j) { int tmp = 0.0; for (int h = 0; h < n; ++h) { tmp += h_a[i * n + h] * h_b[h * k + j]; } h_result[i * k + j] = tmp; } } }