C/C++通用构建加速方法
C/C++编译基本原理
对于C/C++代码通常来说整个构建过程分为以下几个主要部分:
预处理
在此阶段主要完成的工作是将头文件展开、替换宏指令、条件编译展开、消除注释。
编译
在此阶段主要将预编译好的文件转换成汇编语言(高级语言->LLVM平台无关语言->平台汇编语言)。
汇编
在此阶段将汇编语言转换为二进制机器语言。
链接
将编译产物和预编译制品(.o、.a、.so)“拼”成可执行文件,具体一些就是为main编译过程中每一个未定义的符号去编译产物中挨个寻找相应的实现代码,补全符号地址信息。
在编译耗时分析中也就应该对以上几个主要方面分别进行时间维度的评估,逐渐细化分析粒度确定时间瓶颈,直到某个文件、某个函数、某个模板才能有针对性地制定从宏观的构建系统到微观的文件、符号的具体优化方案。
预处理
gcc -E选项可以得到预处理后的结果,扩展名为.i 或 .ii。一般来说对预处理阶段的分析尤为重要,因为预处理完了之后的中间文件才是真正编译过程的输入。预处理后文件的体量大小直接影响了后续阶段各个部分的时间消耗水平。由于C/C++编译特点的影响,每个编译单元(源文件),都需要独立解析所有包含的头文件。也就是说如果N个源文件引用到了同一个头文件,则这个头文件需要解析N次。如果头文件中有模板(STL/Boost),则该模板在每个cpp文件中使用时都会做一次实例化,N个源文件中的std::vector会实例化N次。通常来说预处理阶段资源消耗是否合理一般可以通过以下几个具体指标进行查看。
- 单个源文件头文件引用总数
- 单个头文件被引用总数
编译
gcc -S选项可以得到编译后的汇编代码文件,扩展名为.s。在该阶段中,GCC为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对编译时间,目标文件长度,执行效率这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类:
- 精简操作指令。
- 尽量满足CPU的流水操作。
- 通过对程序行为地猜测,重新调整代码的执行顺序。
- 充分使用寄存器。
- 对简单的调用进行展开等等。
而使用编译器提供的优化选项有时也可能需要再别的地方做取舍。部分优化选项会精简指令改变代码执行顺序,这会导致程序的可调试性大幅降低。另外一些涉及对寄存器、内存进行优化的指令可能会使程序在内存或者寄存器中结果的正确性得不到保障,这也是偶尔会在涉及到寄存器操作的代码中看到Volatile关键字的原因之一。
为了简化用户操作,GCC也提供了相应的一些预设优化方案例如O0~03
- O0:不做任何优化,这是默认的编译选项。
- O和O1:对程序做部分编译优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。
- O2:是比O1更高级的选项,进行更多的优化。GCC将执行几乎所有的不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环展开以及函数内联优化。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。
- O3:在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。
- Os:主要是对代码大小的优化, 通常各种优化都会打乱程序的结构,让调试工作变得无从着手。并且会打乱执行顺序,依赖内存操作顺序的程序需要做相关处理才能确保程序的正确性。
汇编
gcc -c选项可以得到汇编后的结果文件,扩展名为.o。.o文件,是按照的二进制编码方式生成的文件。在这个阶段中可以做的优化方案并不多,所以暂时只需要了解该阶段的基本作用即可。
链接
简单的讲,链接器的工作就是解析未定义的符号引用,将目标文件中的占位符替换为符号的地址。链接器还要完成程序中各目标文件的地址空间的组织,这可能涉及重定位工作。在C./C++程序的链接过程中主要涉及以下角色:
- 静态库:指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了,其后缀名一般为“.a”。
- 动态库:在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可执行文件比较小,动态库一般后缀名为“.so”。
- 可执行文件:将所有的二进制文件链接起来融合成一个可执行程序,不管这些文件是目标二进制文件还是库二进制文件。
C++编译特性
编译单元
C/C++的编译系统和其他高级语言存在很大的差异,其他高级语言中,编译单元是整个Module,即Module下所有源码,会在同一个编译任务中执行。而在C/C++中,编译单元是以文件为单位。每个.c/.cc/.cxx/.cpp源文件是一个独立的编译单元,导致编译优化时只能基于本文件内容进行优化,很难跨编译单元提供代码优化。
头文件解析
如果N个源文件引用到了同一个头文件,则这个头文件需要解析N次。
如果头文件中有模板(STL/Boost),则该模板在每个cpp文件中使用时都会做一次实例化,N个源文件中的std::vector会实例化N次。
模板函数实例化
在C++ 98语言标准中,对于源代码中出现的每一处模板实例化,编译器都需要去做实例化的工作;而在链接时,链接器还需要移除重复的实例化代码。显然编译器遇到一个模板定义时,每次都去进行重复的实例化工作,进行重复的编译工作。此时,如果能够让编译器避免此类重复的实例化工作,那么可以大大提高编译器的工作效率。在C++ 0x标准中一个新的语言特性 – 外部模板的引入解决了这个问题。
在C++ 98中,已经有一个叫做显式实例化(Explicit Instantiation)的语言特性,它的目的是指示编译器立即进行模板实例化操作(即强制实例化)。而外部模板语法就是在显式实例化指令的语法基础上进行修改得到的,通过在显式实例化指令前添加前缀extern,从而得到外部模板的语法。
- 显式实例化语法:template class vector。
- 外部模板语法:extern template class vector。
一旦在一个编译单元中使用了外部模板声明,那么编译器在编译该编译单元时,会跳过与该外部模板声明匹配的模板实例化。
耗时分析工具
-ftime-trace
clang-9中增加了一个选项可以产生编译耗时的具体详情,通过在编译的时候增加这个选项,我们可以找到程序真实瓶颈。
通过命令clang++ -ftime-trace -c ./main.cpp -o test 可以在编译的过程中多得到一个.json文件,简单的处理方法是直接拽到chrome://tracing里分析 一个简单的使用cout的hello world的编译耗时如下图所示:
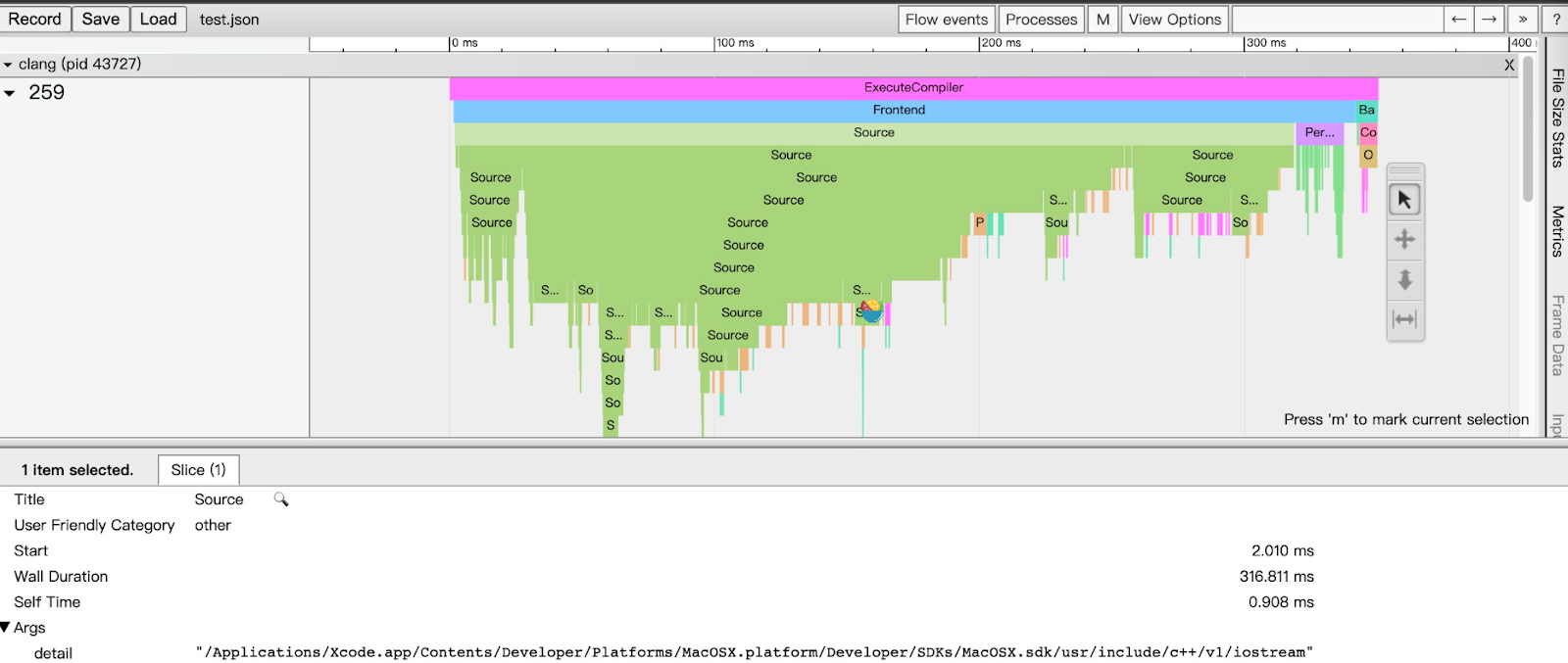
由此可以通过火焰图直观地分析出编译中各个过程,找出时间消耗的瓶颈。
Clang Build Analyzer
对于较为大型的项目来说,往往有成千上万个源文件,相应地在编译过程中也就会生成相当数量的.json文件,显然无法直接分析。此时就可以使用Clang Build Analyzer来汇总所有的json文件对整个工程的构建时间消耗进行分析。通过分析最终可以获得以下对于耗时瓶颈分析十分重要的信息:
哪些文件的解析速度最慢? 例如,花时间在编译器前端(lexer/解析器)上时间最多的文件。
哪个C++模板的实例化时间最长?
哪些文件生成代码的速度最慢? 例如,花时间在编译器后端进行代码生成和优化时间最长的文件。
哪些函数生成代码的速度最慢?
在整个构建过程中,哪些头文件被包含得最多,解析它们花费了多少时间,它们的包含链是什么?
使用条件
由于该工具是通过分析clang生成描述编译过程的.json文件,所以需要clang支持-ftime-trace参数,更加明确一点就是clang版本需要>=9.0.0
使用方法(以标准cmake工程为例)
创建build目录,并启动ClangBuildAnalyzer开始记录时间戳
1 | |
执行构建
1 | |
构建结束后停止记录,并把数据保存在二进制文件内
1 | |
对数据执行分析
1 | |
Include What You Use
这是一个用于分析和管理头文件依赖的工具,具体的描述如下:对于在 foo.cc (或 foo.cpp)中使用的每个符号(类型、函数、变量或宏) ,foo.cc 或 foo.h 都应该包含一个。导出该符号声明的 h 文件。(类似地,对于 foo_test.cc,或者 foo_test.cc 或 foo.h 应该包括在内。)显然,在 foo.cc 中定义的符号被排除在这个需求之外。这使头文件依赖处于这样一种状态,即每个文件都包含声明其所使用的符号所需的标头,而不必担心意外地破坏该文件的向上依赖关系。还可以轻松地自动跟踪和更新源代码中的依赖项。
利用这个工具可以比较方便地扫描出哪些头文件是多余的,哪些是需要的,开发者可以由此为依据调整头文件依赖关系,减少冗余头文件依赖,简化依赖管理过程,同时也可以减少构建的预处理过程中代码膨胀程度,加快编译构建速度。
使用方式(以标准cmake工程为例)
构建iwyu时需要与构建工具链的clang版本对齐,否则可能会导致程序运行结果与运行构建环境不匹配的情况(例如出现了很多不存在的头文件)先执行一次完整的构建,然后用iwyu来分析构建的中间文件(比如compile_commands.json)建议直接使用iwyu提供的python脚本进行分析。
1 | |
分析结果类似如下
1 | |
获取输出的分析结果后不建议直接自动修改头文件引用,因为可能会出现意料之外的问题,同时也可能降低代码的可读性。一般来说作为一个头文件引用参考会比较好,然后根据这个分析结果手动调整依赖关系。
优化与加速手段
并行构建
**适用条件:**计算资源充足
**常规方法:**使用-j参数执行make,尽可能地利用计算资源。
**再进一步:**如果采用标准cmake组织的工程,可以尝试使用ninja替换make进行构建操作,得益于ninja出色的依赖分析再构建时可以得到更好的并行度。相对于用make构建只需要做很少的改变:首先在cmake时用-G指定Ninja,用cmake生成ninja.build(作用类比于makefile),然后ninja -jxxx就可以开始构建了。
**代码优化:**减少串行依赖和间接依赖。
**进阶策略:**可以尝试类似于catkin的并行构建思想,除了单个target或者package中代码的并行构建,还可以把各个package的构建并行,可以获得更好的并行程度。但是为了实现模块的并行构建,需要额外维护一份模块间依赖关系的描述文件,例如catkin中的package.xml文件。
CCache编译缓存
ccache是一个编译缓存工具,其原理是将cpp的编译结果保存在文件缓存中,以后编译时若对应文件无变动可直接从缓存中获取编译结果。需要注意的是,Make本身也有一定缓存功能,当目标文件已编译(且依赖无变化)时,若源文件时间戳无变化也不会再次编译;但CCache是按文件内容做的缓存,且同一机器的多个项目可以共享缓存,因此适用面更大。
使用ccache -s可以查看当前ccache信息,例如剩余缓存空间、命中率等数据。
单机构建:可以通过提高ccache空间来提高命中率。
集群构建:可以尝试使用redis来做ccache存储空间,让构建集群共享编译缓存。
预编译头文件(PCH)
该方法预先将常用头文件的编译结果保存起来,这样编译器在处理对应的头文件引入时可以直接使用预先编译好的结果,从而加快整个编译流程。有的头文件包含了巨量的源代码(如著名的windows.h),或者使用模板编程时要生成巨大的头文件模板库(如Eigen math library与Boost C++ libraries)。为减少编译时间,某些编译器允许把头文件编译为某种中间形式称为预编译头(precompiled header),后续再编译源文件时就可以尽量直接使用这些预编译头。
使用方法(以标准的cmake工程为例)
环境要求:CMake >= 3.16
确认需要使用PCH特性的头文件,针对头文件所在的target按照如下方式修改cmake
1 | |
对于有特定语言要求的头文件需要手动指定出是C或者C++
1 | |
如果有别的模块需要使用之前预编译好的头文件,按如下方式修改cmake
1 | |
module编译
如果项目是用C++ 20进行开发的,那么Module编译也是一个优化编译速度的方案,C++20之前的版本会把每一个cpp当做一个编译单元处理,会存在引入的头文件被多次解析编译的问题。而Module的出现就是解决这一问题,Module不再需要头文件(只需要一个模块文件,不需要声明和实现两个文件),它会将你的(.ixx 或者 .cppm)模块实体直接编译,并自动生成一个二进制接口文件。import和include预处理不同,编译好的模块下次import的时候不会重复编译,可以大幅度提高编译器的效率。
外部模板
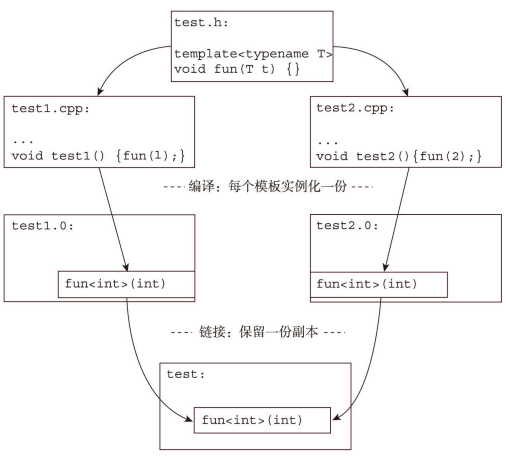
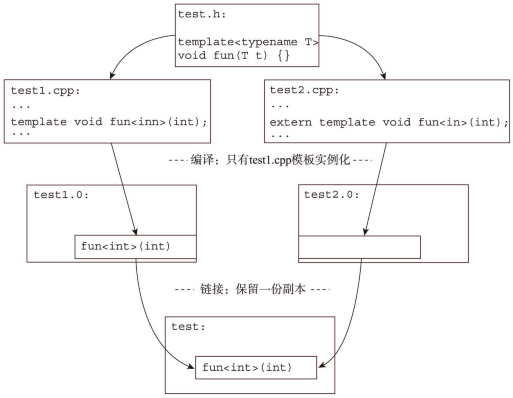
在执行构建耗时分析后,如果发现编译后端耗时过高可以尝试罗列一下模板实例化的top项。以Clang Build Analyzer的分析结果为例,经常会发现有的模板被重复实例化了几十上百次。由于模板被使用时才会实例化这一特性,相同的实例可以出现在多个文件对象中。编译器要对每一处模板进行实例化,链接器还要移除重复的实例化代码。当在广泛使用模板的项目中,编译器会产生大量的冗余代码,这会极大地增加编译时间和链接时间。而在C++11中的”外部模板“就是一个关于模板性能上的改进。
在使用外部模板之前,代码构建过程如下图:
而在使用外部模板之后:
具体实现
extern_template.h 外部模板头文件
1 | |
extern_template.cpp 实例化
1 | |
main.cpp 外部模板声明与应用
1 | |